

Cuando lanzamos Callbook AI, la meta era clara: llamadas con IA que se que sonaran como humanos. Sin embargo, muy pronto nos dimos cuenta de que un enemigo silencioso estaba disparando nuestros costos: el voicemail. En este artículo profundizaremos en la historia real detrás de nuestro problema, el desglose de costos de una llamada IA, por qué las soluciones convencionales fallaban en Latinoamérica y, finalmente, cómo implementamos tinyML para convertirnos en los más competitivos del mercado.
1. El choque con nuestro mayor desafío: el buzón de voz
A mediados de 2024, nuestros primeros clientes ya estaban haciendo decenas de llamadas diarias. En un escenario típico de llamadas en frío, apuntábamos a contactar al 30 % de los números marcados, pero descubrieron que el 70 % restante se perdía en colgadas o directamente en buzón de voz. Lo que más nos llamó la atención fue este dato:
Más de la mitad de esas llamadas “perdidas” —un 50 %— eran mensajes de voz.
Cada vez que esto pasaba, nuestra plataforma ejecutaba todo el flujo de IA (conexión telefónica, transcripción, análisis de texto y generación de voz), aunque al final no interactuara con una persona. El resultado fue que las facturas mensuales se disparaban y muchos clientes empezaban a preguntarse si realmente estaban obteniendo valor de sus campañas.
2. Desglose de costos de una llamada IA
Para entender el problema, veamos cada componente y su modelo de facturación:
- Telefonía (Twilio, Vonage, Zadarma)
- Cobran por segundo o por minuto completo.
- Si la llamada dura 2 s, se factura como 60 s en algunos planes.
- STT (Speech-to-Text)
- Procesa y transcribe toda la señal de audio capturada.
- Se paga por minuto de audio transcrito.
- LLM (Large Language Model)
- Analiza el texto resultante y decide la acción siguiente.
- El precio varía según el modelo (GPT-3.5 vs GPT-4, por ejemplo) y la latencia; más complejidad = más costo.
- TTS (Text-to-Speech)
- Genera la respuesta de voz.
- También se factura por segundo de audio sintetizado.
Caso típico de voicemail
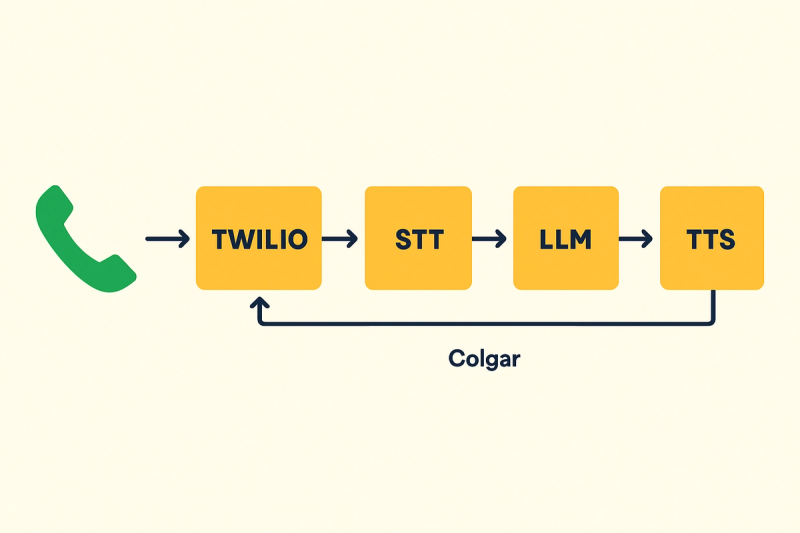
Llamada entra → Twilio cobra por minuto completo → STT transcribe 10 s de… “Beep. Lo sentimos, no puede atender su llamada” → LLM detecta buzón → TTS dice “Adiós” → fin de llamada.
Cada uno de esos pasos consume tiempo facturable: cada voicemail cuesta casi lo mismo que una llamada exitosa.
3. ¿Por qué la AMD de Twilio no resolvía el problema?
Twilio ofrece AMD (Answering Machine Detection), pero:
- Modelos entrenados en mercados anglosajones, donde los patrones de voicemail (tono, duración del beep, pausas) son homogéneos.
- En Latinoamérica existe una gran diversidad de mensajes pregrabados: distintos idiomas (“mensaje en español”), melodías, beeps múltiples, mensajes personalizados de operadoras regionales…
- Resultado: AMD se equivocaba o tardaba demasiado, dejando pasar voicemails a nuestro pipeline de IA.
La práctica común en otras plataformas de AI calls es poner un prompt tipo:
“Si detectas voicemail, por favor cuelga y di adiós”.
Pero, ¿qué ocurre?
El LLM sigue cargado:
- Cobro por prompt + tiempo de inferencia.
El TTS genera el “Adiós”:
- Cobro adicional por síntesis.
El cliente paga.
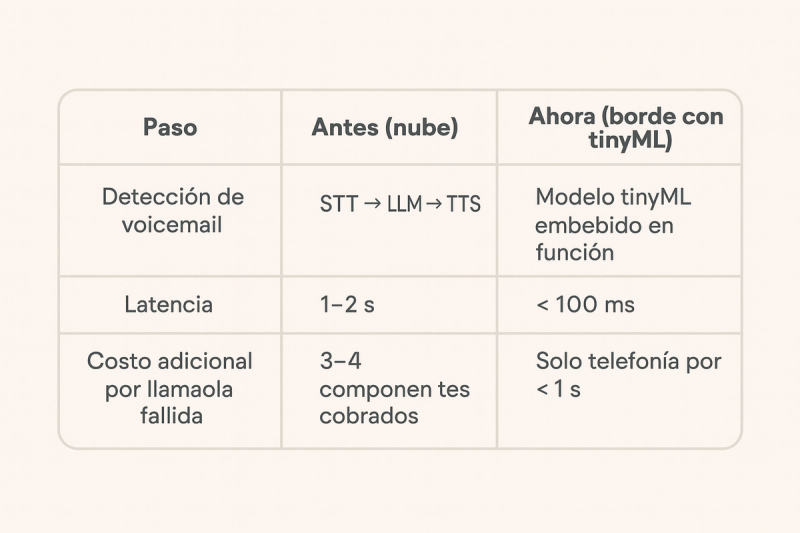
4. TinyML: procesamiento en el borde (edge)
Para recortar todos esos costos innecesarios, diseñamos una solución basada en tiny machine learning que corre localmente en el primer segundo de cada llamada:
5. Construcción de nuestro detector con tinyML usando EdgeImpulse (versión simplificada)
Para que sea más claro, dejamos de lado términos muy técnicos y nos centramos en lo esencial: cómo enseñamos a nuestra IA a distinguir un buzón de voz de una persona que contesta.
5.1. Recolección y organización de ejemplos
- Grabaciones reales: juntamos cientos de clips de buzones de voz de operadoras en Colombia, México, Argentina y Chile.
- Variación natural: incluimos mensajes con distinto ritmo, tonos y música de fondo.
- Clasificación manual: escuchamos cada clip y lo marcamos como “humano” (persona que contesta) o “buzón de voz”.
5.2. Señales de audio que usamos
En lugar de procesar todo el sonido completo, nos fijamos en detalles simples y fáciles de calcular en el momento:
- Pausas y beeps: un mensaje de buzón suele tener cortes y señales fijas (el famoso “beep”).
- Ritmo de la voz: las personas hablan de forma más irregular que los mensajes grabados.
5.3. Un modelo muy ligero
- Creamos un pequeño programa de apenas unos cientos de kilobytes.
- Antes de cualquier paso en la nube, el detector analiza el primer segundo de audio y decide: ¿voz humana o buzón?
- Si es buzón, cortamos la llamada de inmediato.
5.4. Entrenamiento y resultados
- Entrenamiento: usamos 80 % de los ejemplos para “enseñar” al modelo y 20 % para “probar” su precisión.
- Precisión: acertamos en más del 96 % de los casos.
- Falsos negativos (buzón no detectado): quedaron por debajo del 1.5 %.
6. Resultados finales y métricas clave
Después de entrenar e integrar nuestro detector ligero, obtuvimos:
- Accuracy (precisión) de 91,4 %: esto significa que, de cada 100 llamadas que realmente iban a buzón de voz, nuestro modelo identificó correctamente 91 de ellas.
- Loss (pérdida) de 0,35: es una medida de qué tan “seguro” está el modelo cuando clasifica cada muestra. Un valor de 0,35 indica un buen balance entre aprender patrones y no sobreajustarse a ejemplos puntuales.
¿Por qué importan estos números?
- Con una precisión superior al 90 %, reducimos drásticamente los “falsos positivos” (llamadas a personas marcadas como buzón) y también minimizamos los “falsos negativos” (buzones no detectados).
- Un loss moderado nos asegura que el detector generaliza bien: no confunde ruidos o tonos de espera con mensajes de voz, manteniendo el detector fiable incluso en condiciones distintas a nuestro set de entrenamiento.
Gracias a esa eficacia, en producción vimos:
–60 % en el gasto asociado a llamadas que terminan en buzón de voz.
En otras palabras, al cortar cada voicemail en el borde antes de pasar por STT, LLM o TTS, ahorramos más de la mitad de los costos que antes se iban en procesamientos innecesarios. Este ahorro se traduce directamente en facturas más ajustadas y clientes mucho más tranquilos con el retorno de inversión de sus campañas.